I want to have a simnple web service that can take my digital voice recored (hereafter dvr) and transcribe to text, send transcription (after my approvall?) to a llm like chatgpt or gemini or whavs, returning a summary, a summary half as long/twice as condensed, and optionally the soundtrack files, and optionally in other format/styles, return by emaik, or ideally direct to my preferred local storage (or why not just cloud? or hwy not pboth
chatgpt to summarizze; look at filename or other metadata for instucitno, for instance, if the filename or metad has “letter-to-editor”, then the results are returned as a leteer to the editor, or “letter to mom”, even having it guess by looking at content and past content, earning each detinees style of conversation.
currrntly i do the following manually
- Copy file from my dvr to my PC
- upload audio fiiles to AWS bucket
- on aws, create a transcription job, manually filing the details;
- I can do this at a rate of 10 ramblings in 15 minutes if nbot distracted; but tedious
- maybe name the files by the first 10 weords?
- summerizer steps below via llm probs do a bestter job
- maybe have it pause with suggestin? job transcribe is done, then make it wait until confirmation of nameine; this is important be cause so much can be done just with filenme system, not thing external, ex. maybe better use of properties llike os/2 metadata
- on competion (no mre than a minute so far), download the 3 files
- aws bucket explorer doesn’t let multiselected files to be downloads, so one at a time ffs
- aws returns the transcription in .json format, so need to extract the text
- should be trivial with python, or aws tools?
- send the transcripts to me by email
- email easy
- ideally files would be stored locally or in google drive or othjer cloud service
- better: mkae a post to blog or notion or wheves?
2024-04-09 – do 20 transcriptions manual, 2 x ~15 minutes each 10
2024-04-10 – did 10 more manual transcription jobs:
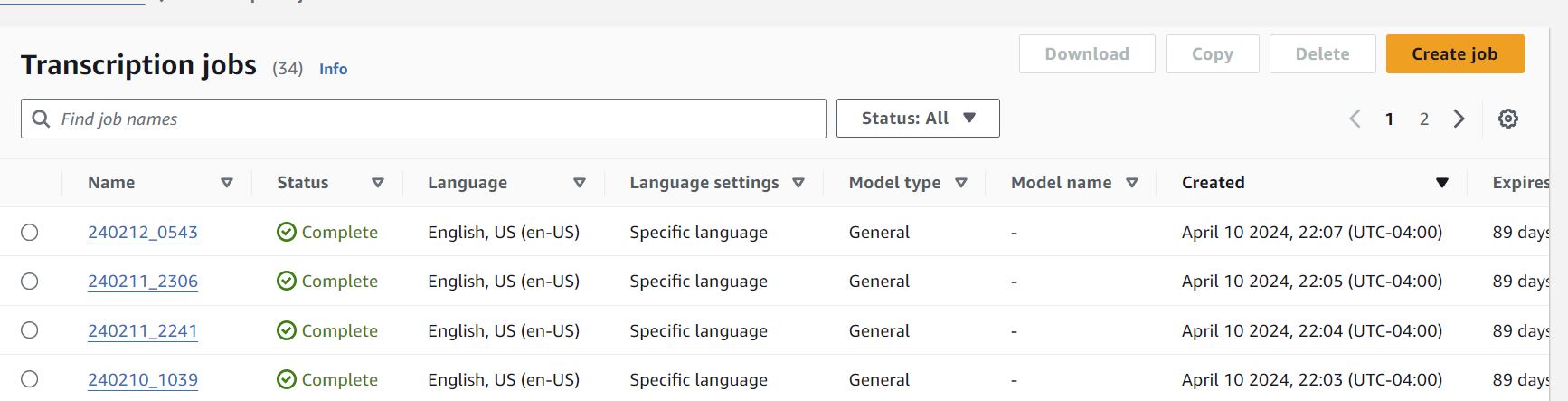
with 79 files in my output bucket:
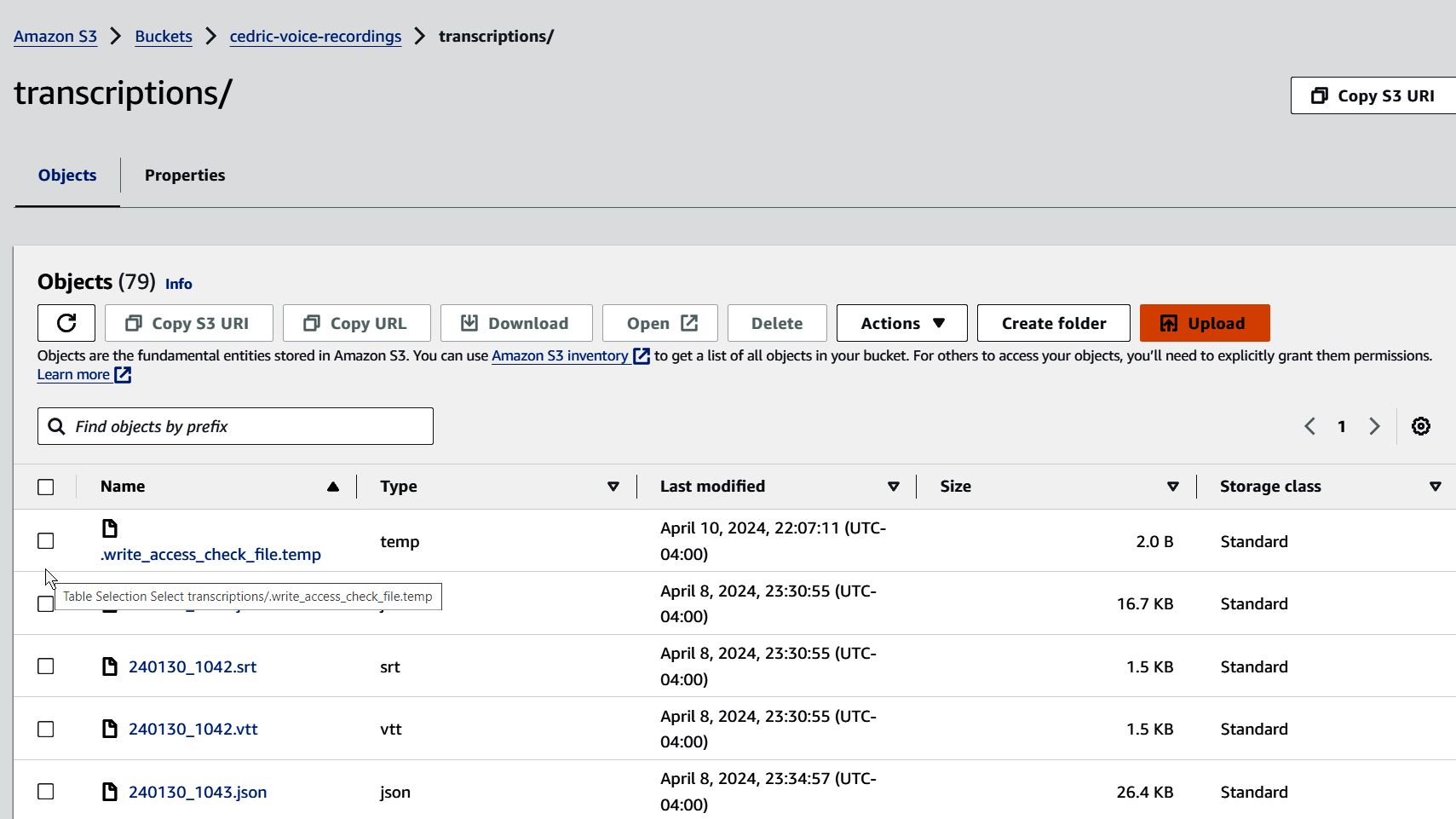
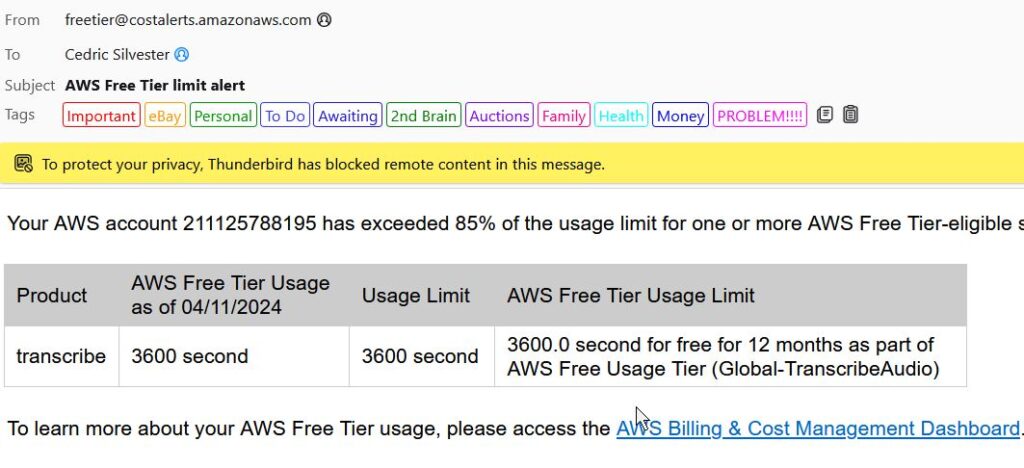
2024-04-11 – further work on documenting how I do this manually using AWS Free Tier
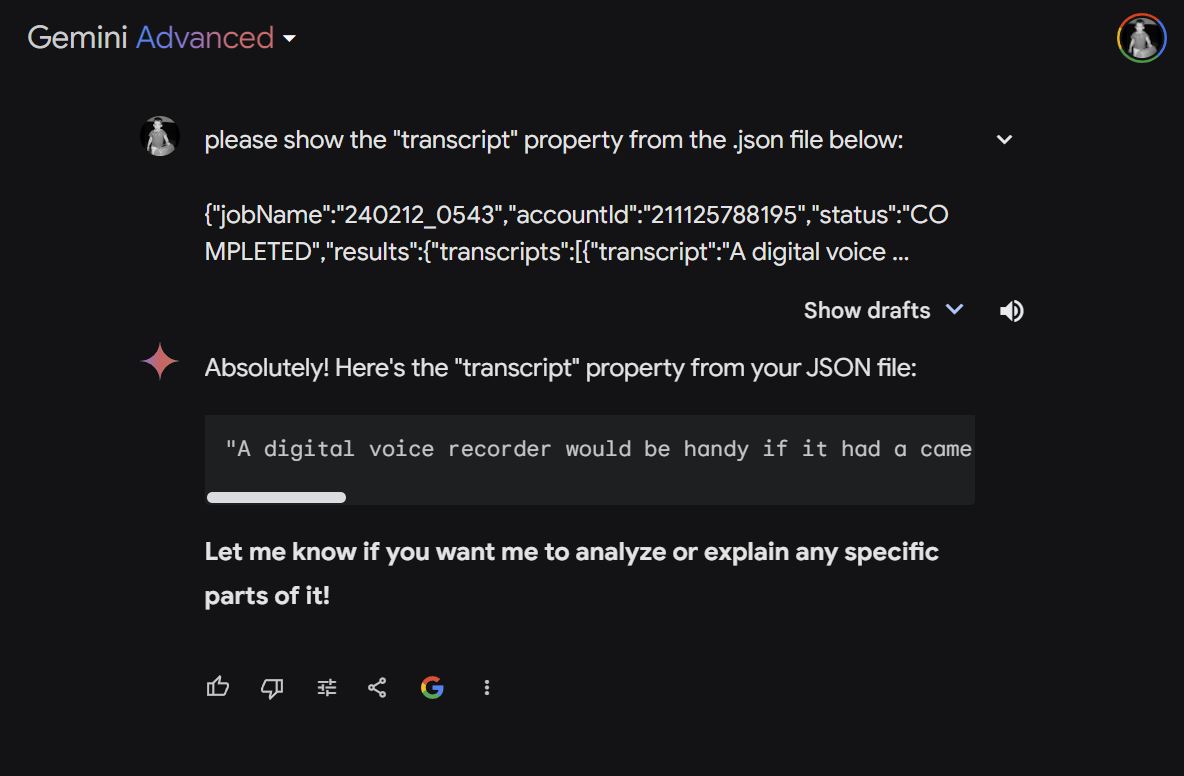
extracting text of the transcription from a .json file is trivial; Gemini+ did it:
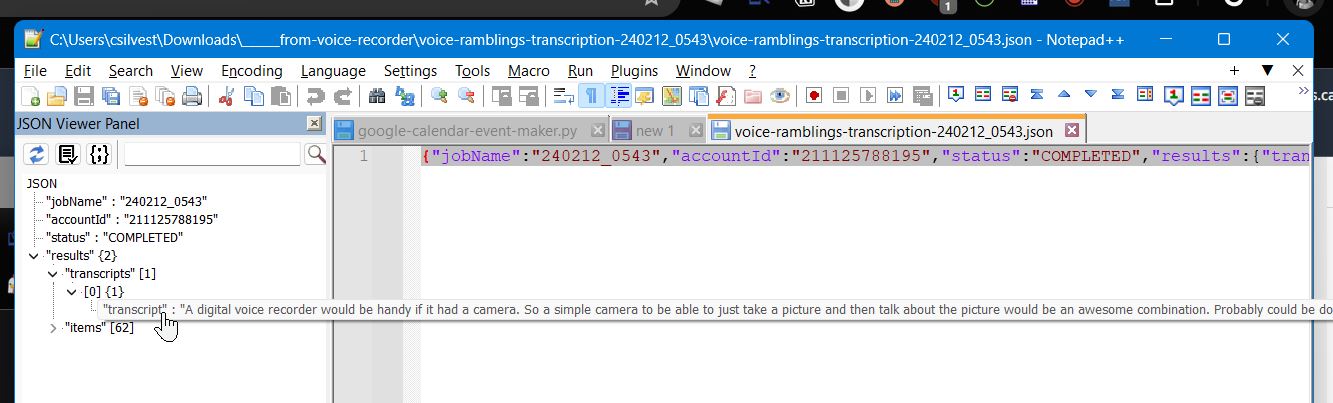
as can a .json file viewer:
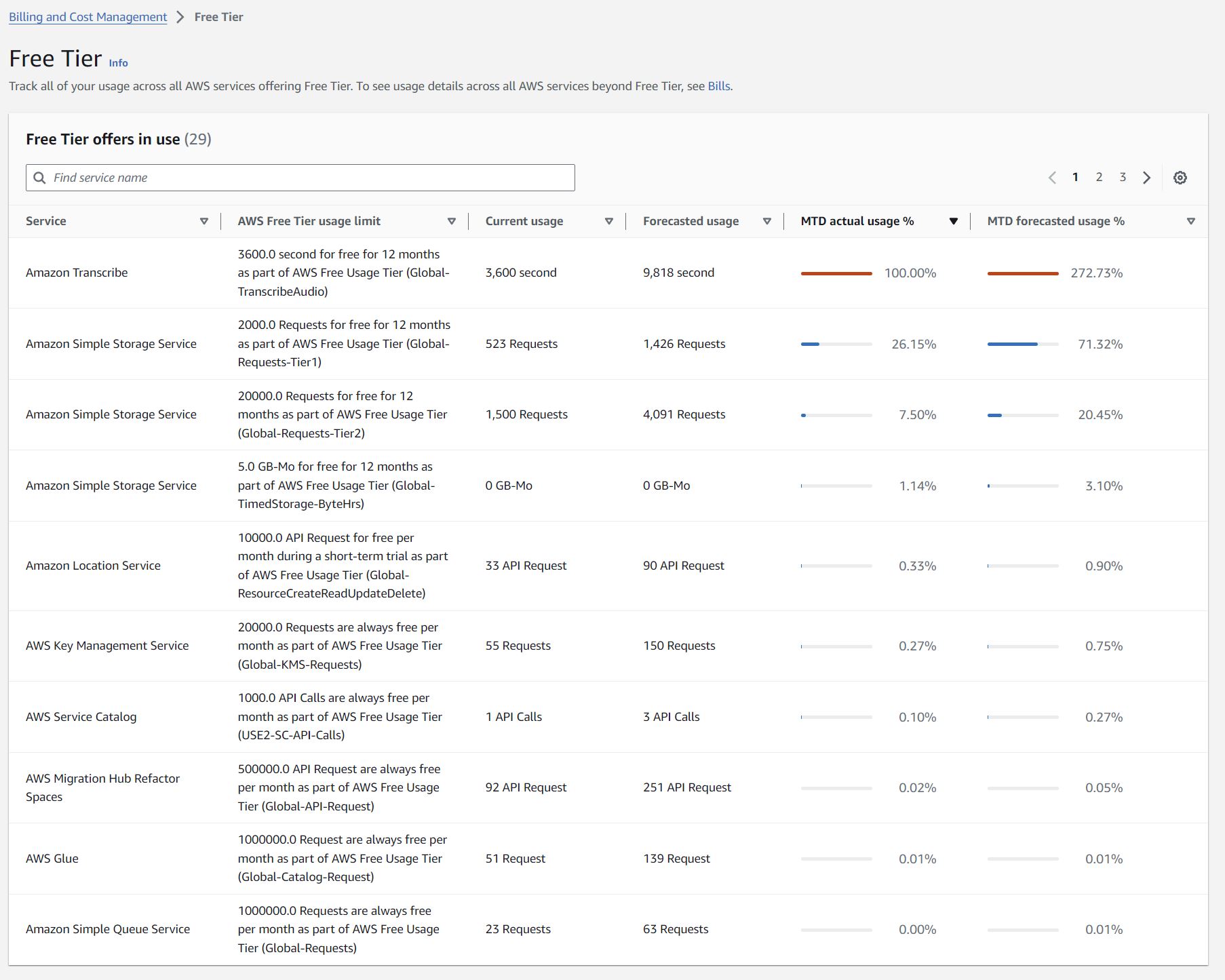
2024-04-11 – i’ve bumped into my limit for tranjscriptions; 3600 seconds ( 60 mins), whcih might be the time of the audio playing time of the ~40 I did last few days?